About Kubernetes
For years Google is driving its infrastructure using containers with a system named Borg, they are now sharing their expertise with an Open Source container cluster manager named Kubernetes (or helmsmen in ancient greek) abreviated k8s. Briefly said Kubernetes is a framework for building distributed systems.
Release 1.0 went public in July 2015 and Google created at the same time, in partnership with the Linux Foundation, the Cloud Native Computing Foundation (CNCF).
If you want to know more, read on.
A bit of reading first
The objective of Kubernetes is to abstract away the complexity of managing a fleet of containers. By interacting with a RESTful API, you can describe the desired state of your application and k8s will do whatever necessary to converge the infrastructure to it. It will deploy groups of containers, replicate enough of them, redeploying if some of them fails, etc…
By its open source nature, it can run almost anywhere, public cloud providers all provide easy ways to consume this technology, private clouds based on OpenStack or Mesos can also run k8s, bare metal servers can be leveraged as worker nodes for it. So if you describe your application with k8s building blocks, you’ll then be able to deploy it within VMs, bare metal server, public or private clouds.
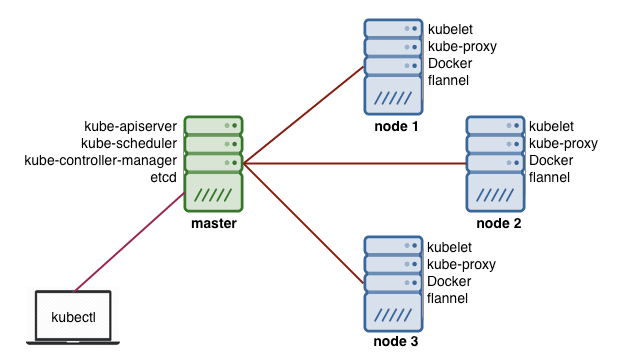
Kubernetes architecture is relatively simple, you never interact directly with the nodes that are hosting your application, but only with the control plane which present an API and is in charge of scheduling and replicating groups of containers named Pods. Kubectl is the command line interface you can use to interact with the API to share the desired application state but also gather detailed information on the current state.
Nodes
Each node that are hosting part of your distributed application do so by leveraging Docker or a similar container technology like Rocket from CoreOS which by the way offer a supported version of Kubernetes. They also run two additional piece of software, kube-proxy which give access to your running app and kubelet which receive commands from the k8s control plane. They can also run flannel, an etcd backed network fabric for containers.
Master
The control plane itself runs the API server (kube-apiserver), the scheduler (kube-scheduler), the controller manager (kube-controller-manager) and etcd a highly available key-value store for shared configuration and service discovery implementing the Raft consensus Algorithm.
Terminology
Pods - group of one of more containers, shared storage and options about how to run them. One IP per pod gets assigned.
Labels - key/value pairs that are attached to any objects, such as pods, Replication Controllers, Endpoints, etc..
Annotations - key/value pairs to store arbitrary non-queryable metadata.
Services - an abstraction which defines a logical set of Pods and a policy by which to access them
Replication Controller - ensures that a specific number of pod replicas are running at any one time.
Secrets - hold sensitive information, such as passwords, TLS certificates, OAuth tokens, and ssh keys.
ConfigMap - mechanisms to inject containers with configuration data while keeping containers agnostic of Kubernetes.
Why Kubernetes
In order to justify the added complexity that Kubernetes brings, their need to be some benefits. At its core a cluster manager like k8s exist to serve developpers, so if they can serve themselves without having to refer to the operation team it will create a new experience for developpers. But that kind of developper Self Service may not be what your organisation wants.
Reliability is a big part of the benefits of Kubernetes, Google have over 10 years of experience when it comes to infrastructure operations with Borg their internal container orchestration solution and they’ve built k8s based on this experience. Kubernetes can be used to make failure not impact the availability or performance of your application, that’s a great benefit.
Scalability is handled by Kubernetes on different levels, you can add cluster capacity by adding more workers nodes, this can even be automated in public cloud with autoscaling fonctionnality on CPU and Memory triggers. Kubernetes Scheduler feature affinity features to spread your workloads evenly across the infrastructure, maximizing the availability. Finally k8s can autoscale your application using the Pod autoscaller which can be driven by customs triggers.
But all of this needs to be proven to be commonly accepted, while setting up a cluster for a proof of concept it’s really important to precisely define the acceptance criteria, with very specific expectations.
Pod Patterns
When we think about how to best build a Pod, different patterns emerge, for example
- sidecar containers - extend and enhance the main container
- ambassador containers - offer a local proxy to the world, connection can then be opened on localhost because containers within the same Pod share the same IP.
- adapter containers - standardize/normalize output
Breaking out your application stack in smaller components will require careful thinking, but the way you can try, fail fast on such a dynamic k8s system, will help you find the best architecture by trial and error.
You’ll then be able to bundle your application using the Helm Package Manager which is an interesting work in progress from the Deis team.
Kubernetes 1.2
If you are curious to catch-up with the latest and greatest Kubernetes features, here is a quick reminder of what has been added in this release:
- Improved Performance and Scalability - Kubernetes now supports 1000-node clusters and up to 30.000 Pods, over 10 millions requests/seconds. 99% of API calls return in < 1 second, 99% Pods starts in < 5 seconds. Pure iptables kube-proxy (no CPU, throughput or latency impact).
- Deployment - to easily achieve rolling updates with zero downtime
- Horizontal Pod AutoScaler (HPA) - scale the number of pods to a target metric (cpu utilization, custom metrics still alpha in 1.2)
- Auto provisionning of persistent volume (PersistentVolumeClaim) - require a supported cloud GCE, AWS or OpenStack
- Multi Zone Clusters - Zone fault tolerance for your application, also called Ubernetes Light, will be expanded to full Federation in future releases to combine separate Kubernetes clusters running in different regions or clouds. For now a single cluster can have its worker nodes in different zones.
- Ingress - L7 Load Balancing (beta) with SSL support, works today with GCE, AWS, HAproxy, nginx. Maps incoming traffic to services based on Host Headers, URL Paths, … It allows to build the same automation for on premise and off premise, same Load Balancing API everywhere but different implementation, abstracted away.
- Secrets - manage secrets using the same API and kubectl CLI, injected as virtual volume into pods, never touch disks (tmpfs in memory storage). Accessed as files or environment variables from your application.
For more details on all of this, consult this series of in-depth posts or look at the stream of CHANGELOG.
As a quick reminder, k8s v1.1 introduced previously added
- HTTP Load Balancing [beta]
- Autoscaling [beta]
- Batch Jobs
- Resource Overcommit
- IP Table based kube-proxy
- new kubectl tools - run interactive commands, view logs, attack to containers, port-forward, exec commands, labels/annotation management, manage multiple clusters.
- and many more improvements
What’s left to address
Kubernetes is not the end game, developpers are not used to Pods, Replication Controllers and so on, so we need to expose something more familiar to them. We really shouldn’t ask them to change radically their workflow, they like their git push, so instead the technology should be almost transparent to them. Platform as a Service solution that co-exist with k8s could help in that respect.
For example Deis Workflow, built upon kubernetes, CoreOS and Docker, delivered as a set of k8s microservices, makes it simple for developers to deploy their application. Redhat also offer, OpenShift, a PaaS on top of Kubernetes.
Service Discovery could be a DNS service like Consul, an external registry like ZooKeeper or Environment variable injected at bootstrapping time. Kubernetes provide a cluster DNS addon which is using skydns built on top of etcd and kube2sky which talk to the k8s API to provide DNS resolution for containers.
As it stands today Kubernetes doesn’t do edge routing well enough, when it comes to on-premise deployment. Addressing edge routing is essential for the end to end success of hosting your application within a k8s cluster. Ingress are an interesting added feature of k8s v1.2 that need to mature, with a broad ecosystem of Load Balancers, to deliver a robust traffic routing solution for your datacenter.
Manifest Management could be managed in version control but this is something new and needs to be handled with care.
Once you have everything above in place and when your Continuous Integration workflow is humming, you need to monitor all of it carrefully, solutions like Prometheus which is now part of the Cloud Native Computing Foundation could be interesting to look at. Another common alternative is the following triplet cadvisor resource usage and performance characteristics of your running containers + influxdb time series database + heapster Compute Resource Usage Analysis and Monitoring of Container Clusters.
For logging you could leverage fluentd open source data collector + elasticsearch full text search engine + kibana dashboard.
When going to productions more questions arise, what’s the best architecture for your cluster ? how to setup High Availability ? how to test for failures ? how fast can you redeploy your cluster ? how will you be upgrading it without affecting the running applications ? What about the security of the overall system ?
Last one, how will you be addressing Disaster recovery ? Kubernetes self healing internal mechanism won’t be enough when catastrophic failures happens. Sometimes you’ll have to spin up a new cluster from scratch, you’ll need to restore a backup of your cluster configuration to get your application running again. How will you recover application data ?
Conclusion
Kubernetes is a great container orchestration solution but this technology doesn’t apply everywhere. Most legacy application like Oracle or SAP won’t really benefit from it. You really have to select workloads carrefully. Web applications that relies on replicated datastores could be could candidates for example
Don’t make the mistake of overselling it, let the traditionnal IT stuff run untouched, but create a bridge between the different worlds. For example Service Discovery can be leveraged by an application running on k8s to get connection information to an Oracle Database, that’s totally fine.
If you think you can benefit from it, make sure to share and explain the reasons and promote it within your organisation. Sponsorship is key not to see your initiative dying after a while, adoption by a broad set of people is key for its survival.
The world of Kubernetes is moving fast, if you want to get regular updates, read the KubeWeekly newsletter.
Thanks for reading to that end and I wish you good luck with your containers !
Kubernetes Links
- Kubernetes.io
- Kubernetes Getting Started Guides
- Kubernetes source code
- Kubernetes slack channel
- Kubernetes twitter
Other links
- CoreOS - open-source lightweight operating system based on the Linux kernel
- Docker - open platform for developers and sysadmins to build, ship, and run distributed applications
- Calico - A Pure Layer 3 Approach to Virtual Networking
- Tigera - Calico and Flannel networking united
- Deis - open source PaaS built on top of k8s
- Tectonic - CoreOS supported version of k8s
- Kubespray - Deploy a production ready kubernetes cluster with Ansible
- Cloud Native Computing Foundation - facilitate collaboration among developers and operators on common technologies for deploying cloud native applications and services
- Open Container Initiative - lightweight, open governance structure to create open industry standards around container formats and runtime
- Raft - Consensus Algorithm
Blogs
- Official blog
- KubeWeekly
- CoreKube
- Kubernetes networking 101 - internal communication
- Kubernetes networking 101 - external access to the cluster
Books
- Kubernetes: Up and Running - to be published in Aug’16
Online Trainings
- The illustrated Children’s Guide to Kubernetes
- Hello World Walkthrough
- Kubernetes Examples
- Free Udacity Scalable Microservices with Kubernetes
- Kubernetes from the ground up
- About etcd and Raft consensus Protocol
- Raft protocol explained step by step
Online Docs
- Kubernetes
- Kubernetes Cheatsheet
- Kubernetes Debugging FAQ
- etcd - distributed key/value store
- flannel - Overlay Networking
- Helm - The Kubernetes Package Manager contributed by Deis team.
- CNI - Container Network Interface
Events
- Docker and Kubernetes Bootcamp by Mirantis - august 9–10, 2016
- Kubecon - november 8–9, 2016